Le travail par lots
Le travail par lots (Batch processing)
Le traitement par lots est une méthode d’exécution des programmes dans laquelle plusieurs tâches sont regroupées et exécutées automatiquement, sans intervention humaine directe.
Ce modèle domine l’informatique des années 1950 et reste central dans l’informatique de gestion bien après l’apparition des systèmes interactifs, car il est adapté aux traitements répétitifs, massifs et planifiables (états, éditions, clôtures, mises à jour).
Origine du traitement par lots
Les premiers ordinateurs sont coûteux et rares. Chaque minute d’occupation machine doit être “rentabilisée”. Or, dans un usage interactif primitif (un utilisateur à la fois), l’ordinateur passe beaucoup de temps à attendre : chargement, réglages, lecture de supports, impression des résultats.
Le travail par lots répond à ce problème : au lieu de traiter une seule demande à la fois, on prépare une file de jobs et on les exécute en chaîne. L’ordinateur est utilisé de façon plus régulière, et l’opérateur peut organiser le flux d’entrée/sortie.
Fonctionnement typique (époque cartes et bandes)
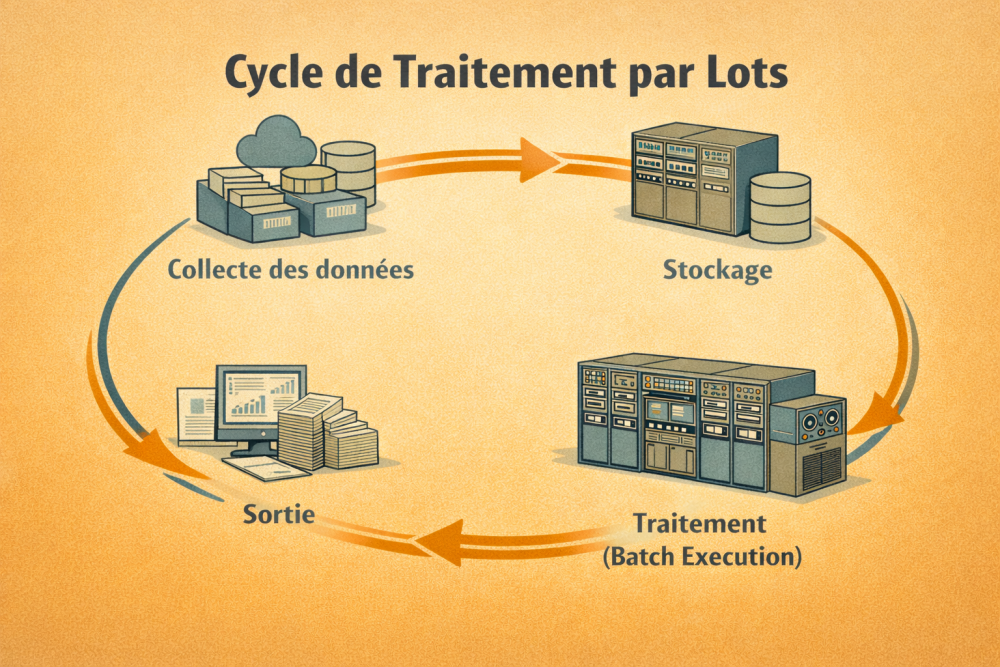
Historiquement, les programmes et données sont souvent fournis sous forme de cartes perforées ou de bandes. Une session batch classique suit ce schéma :
- Préparation : l’utilisateur remet un paquet de cartes (programme, données, paramètres).
- Soumission : le job est ajouté à une file d’attente.
- Exécution : l’ordinateur traite le job sans dialogue utilisateur.
- Sortie : résultats imprimés (listing) ou perforés, puis récupérés plus tard.
L’élément clé est l’absence d’interactivité : pendant le calcul, l’utilisateur ne “voit” pas le programme s’exécuter et ne peut pas corriger en direct. Le cycle test/correction est donc plus lent qu’en time-sharing.
Exemple historique : le traitement par lots sur l’IBM 704
Dans les années 1950, de nombreux ordinateurs scientifiques fonctionnent en traitement par lots. L’IBM 704 en est un exemple typique.
Les programmeurs préparent d’abord leur programme sur des cartes perforées.
Ces cartes sont ensuite regroupées en « lots » contenant plusieurs programmes et leurs données.
L’opérateur charge ensuite ces paquets de cartes dans le lecteur de cartes de la machine.
L’ordinateur exécute alors chaque programme successivement, sans interaction avec l’utilisateur.
Les résultats sont généralement imprimés ou enregistrés sur bande magnétique.
Ce mode de fonctionnement permet d’utiliser efficacement une machine très coûteuse.
En revanche, il impose un délai important entre l’écriture d’un programme et l’obtention du résultat.
Les “moniteurs” : ancêtres des systèmes d’exploitation
Le batch pousse très tôt à créer des programmes résidents appelés moniteurs : ils enchaînent automatiquement l’exécution des jobs. Au lieu de recharger manuellement chaque programme, le moniteur :
- charge un job,
- l’exécute,
- récupère le contrôle à la fin,
- passe au job suivant.
Ces moniteurs sont l’une des origines directes des systèmes d’exploitation : ils gèrent la séquence, les périphériques, et une partie de l’allocation des ressources.
Spooling : la grande amélioration des années 1960
Le batch “classique” souffre d’un problème majeur : les périphériques (lecteurs de cartes, imprimantes) sont très lents par rapport au processeur. Le système perd du temps à attendre les entrées/sorties.
La solution est le spooling (Simultaneous Peripheral Operations On-Line) : au lieu de lire directement les cartes pendant le calcul, on tamponne les entrées sur disque et on imprime les sorties plus tard. Cela permet :
- de découpler calcul et E/S,
- de maintenir le processeur occupé,
- de gérer une file d’attente plus efficace.
Historiquement, on a aussi utilisé des configurations “couplées” où une machine plus petite gère l’entrée/sortie (ex. collecte et impression), pendant que la machine principale calcule.
JCL : décrire un job au système
Dans un environnement batch, le système doit connaître à l’avance ce que le job va faire et quelles ressources il utilisera (fichiers, imprimantes, bandes, priorités). C’est le rôle d’un langage de contrôle de jobs.
L’exemple le plus connu est le JCL d’IBM (Job Control Language), utilisé avec OS/360 et ses descendants. Il permet de décrire une exécution en étapes (compilation, édition de liens, exécution), d’indiquer les fichiers et de spécifier des actions selon succès/échec.
Batch et time-sharing : opposition et coexistence
Le time-sharing (années 1960) naît en grande partie pour réduire la lenteur du cycle “soumettre / attendre / récupérer / corriger” propre au batch. En time-sharing, un utilisateur interagit via un terminal, et le système partage le processeur en tranches de temps.
Mais il est important de noter que les deux modèles ont longtemps coexisté. Même dans des environnements time-sharing, les traitements lourds ou répétitifs restent souvent exécutés en batch, car ils sont plus simples à planifier et à contrôler.
Apport historique du travail par lots
- Industrialisation : l’informatique devient un service organisé (files, priorités, procédures).
- Naissance des OS : moniteurs, gestion d’E/S, ordonnancement.
- Formalisation : description des tâches (JCL), séparation programmes / données.
- Productivité : traitements de masse fiables pour la gestion.
Le batch n’est donc pas seulement “l’informatique d’avant” : c’est un modèle d’exploitation qui a structuré les systèmes d’information et qui reste, sous des formes modernes, indispensable pour de nombreux traitements.